Method
Single Demo, Autonomous Data Collection, Deployment
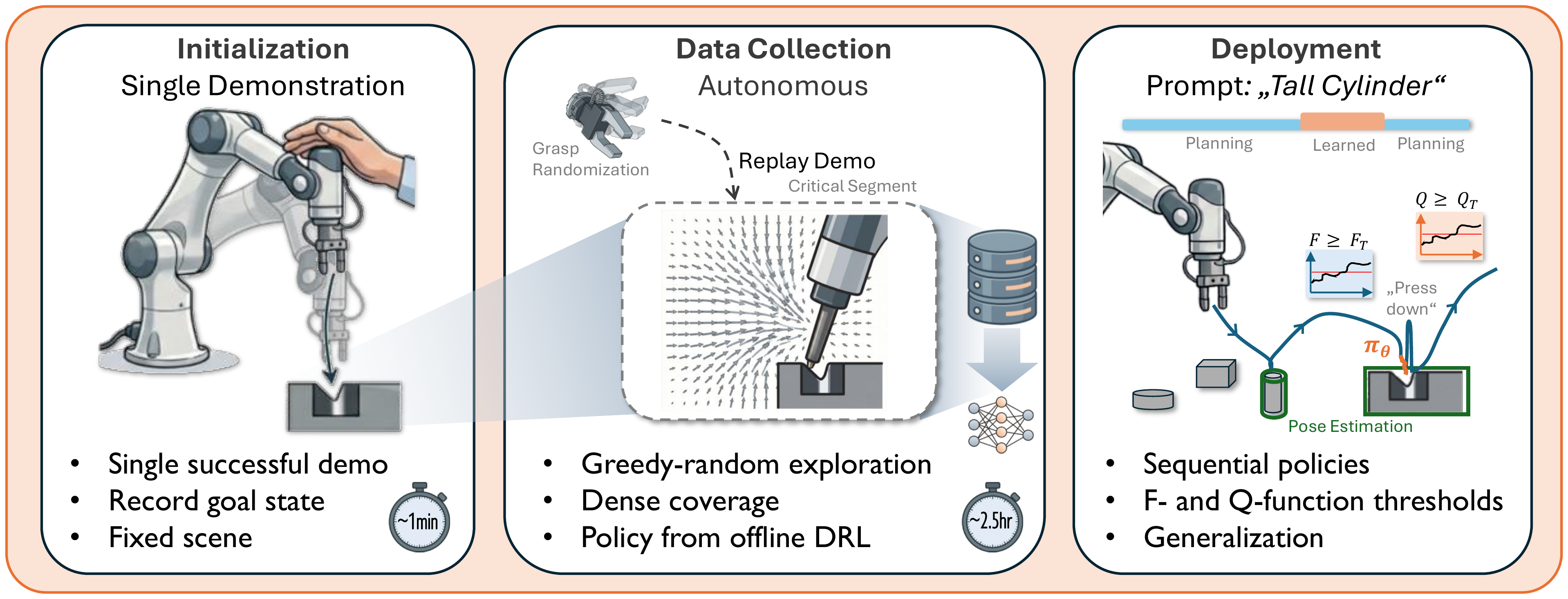
We use expensive robot data only for the most challenging section of the task, and rely on non-robot data wherever possible. The result is a policy that is robust and generalizable, yet very precise.
All videos are sped up.Using natural-language prompts, the robot solves a very long-horizon sequence of challenging high-precision tasks in a changing and cluttered scene — using robot data only where necessary to achieve the required precision. For the rest of the motion, we rely on simple motion planning including collision avoidance.
We never collected any data in this specific scene!
Abstract
Learned policies trained end-to-end on large datasets often remain brittle in high-precision tasks and struggle with generalization. We find that these limitations largely stem from a lack of structure and focus in data collection. Our key insight is to leverage dense data collection only for the critical, contact-rich segment of a task and to rely on traditional planning during simple free-space motion.
We propose an automated data-collection scheme combined with offline deep reinforcement learning for the critical segment — eliminating reliance on a teleoperator's skill and on online policy updates. Across four challenging real-world tasks, using only 2–2.5 h of autonomous data collection, we achieve an average success rate of 96%, compared to the strongest baseline at 55%. Notably, performance remains high in out-of-distribution scenarios where end-to-end approaches struggle.
Robustness & Generalization
Robot data and learning are only used where absolutely required to achieve the necessary precision for our tasks. This approach allows the policy to achieve the required precision while generalizing to entirely novel scenes — settings where end-to-end policies typically fail.
Our method generalizes across dimensions: scene-level distractors (objects and backgrounds), target object location, pick-up object location, collision avoidance, dynamic grasping from a human hand, and sequential task compositions.
Method
Rollouts · Our Method
The key is to leverage dense data collection at the difficult segment, so that the policy never goes out-of-distribution for that part of the task. Success rates below are measured over 50 trials per task.
In the paper, we show that learning with offline DRL from densely collected data is required to achieve high success rates!
(Almost) Autonomous Data Collection
We show that dense data collection through explorative offline DRL is required to achieve high success rates for our tasks. Operator intervention is only required for resetting the scene in some tasks.
All the policies above are deployed using data collected from the setups shown below!
The scene is calibrated using a single human demonstration from kinesthetic teaching. Operator intervention during data collection is only required for resetting the scene for some tasks.
Baselines
The same high-precision and out-of-distribution tasks cause strong end-to-end baselines to fail — they lack precision at the contact segment and break down under distractors. Further, our method naturally provides a success classification through Q-function evaluation.
It is not clear whether simple scaling of end-to-end data collection is practical or solves the performance gap!
For instance, end-to-end policies fail to correctly detect target objects and instead grasp a similar-looking object (bottom right). End-to-end policies need much training data to avoid such failure cases, whereas other models trained without any robot data — such as SAM3 for object detection — are far more robust by default.